Many data scientists today find themselves deploying production solutions using single notebooks, often neglecting encapsulation and code packaging. This approach inevitably leads to challenges in maintainability. As a continuation of our journey from single Python file projects to production-ready code (check out our previous article [Previous article]), this article delves into practical solutions. Today, we'll explore basic strategies for data scientists to effectively automate the packaging of their Python modules. By embracing tools like Makefile and setup.py, we aim to guide you towards a more organized and maintainable approach to Python project management.
To demonstrate these techniques in action, we will be further developing our sample project using the Titanic dataset. While this problem may seem familiar, the focus of this article is on the quality of the code, not the problem at hand. Keep in mind that while the production-ready solution we'll be working towards may be overkill for this non-real-world problem, it serves as a useful example for demonstrating these techniques in practice.
Packaging Python modules using setuptools
Packaging data science Python modules into Python wheels offers streamlined maintainability and robustness for your projects. By encapsulating dependencies, wheels simplify version control, reducing compatibility risks. Furthermore, uploading these wheels to a server like PyPI ensures a centralized repository, facilitating easy sharing, distribution, and seamless installation for collaborators. Embracing Python wheels is not just a packaging choice; it's a strategic move towards efficient management, collaborative workflows, and enhanced reliability in your data science projects.
The process is simple, first ensure that you have installed the Python package setuptools. Next, restructure the Python module directories as below, along with creating a new Python file named setup.py as indicated below.
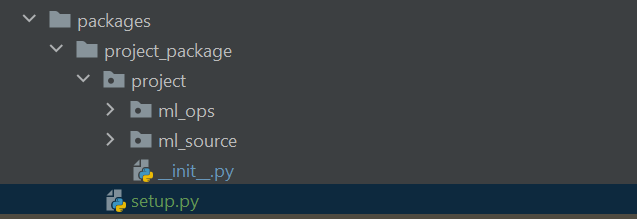
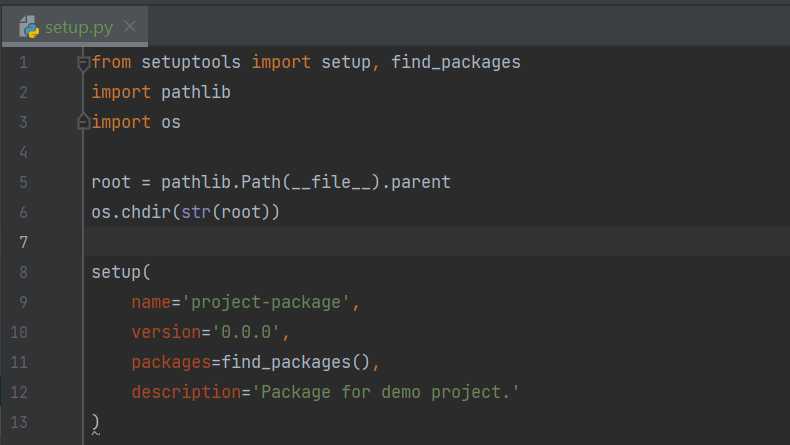
We can then run the setup.py file from the root of the project directory, and several new files and folders will be created, as indicated below:
python3 packages/project_package/setup.py bdist_wheel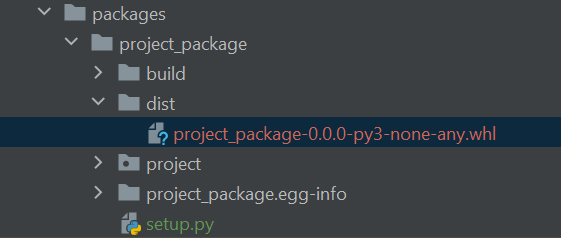
We only need the Python wheel file (file extension .whl), this is the file that we will pip install to install our new Python package, we can do this as follows:
pip install packages/project_package/dist/project_package-0.0.0-py3-none-any.whl --force-reinstallNow we can update our package import paths throughout our codebase to import our Python modules from our installed package instead of the absolute/relative Python imports we were previously using.
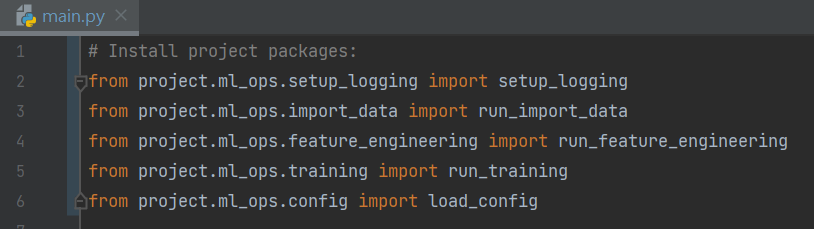
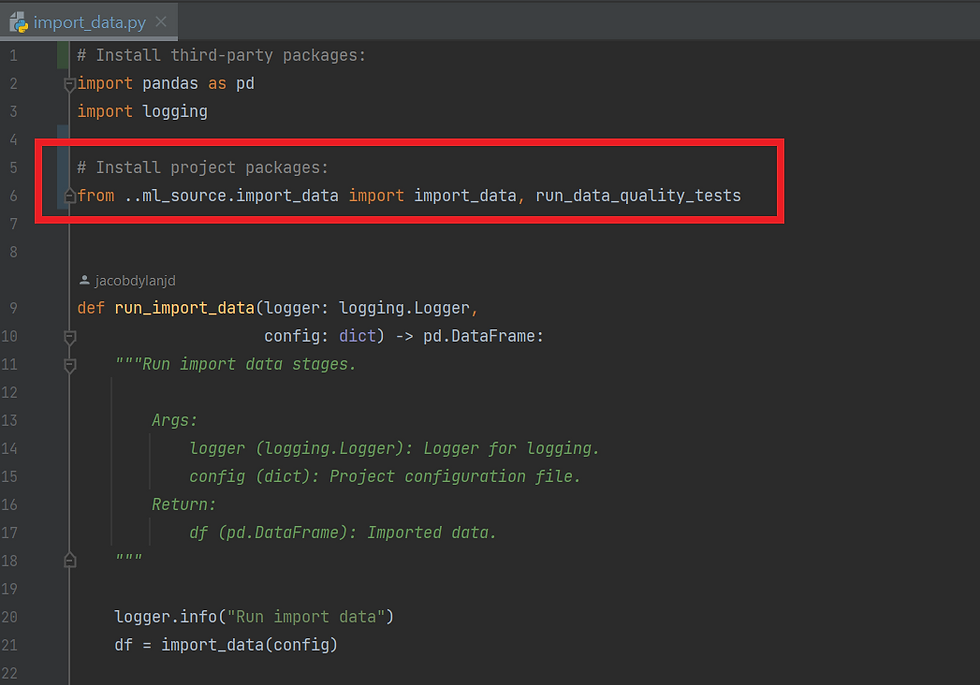
Note, we want to ensure that throughout the python modules we are using relative imports, for example the function run_import_data() is a function within our Python package, this also uses a function called import_data(), we use a relative import for this as indicated below. Using relative imports throughout a Python package ensures that the module maintains its structure and dependencies when installed in different environments.
In a real world project, it is recommended to next setup a private package management server such as PyPI, allowing you to upload your python wheel. This centralized repository approach will allow you and others to pip install your package directly from PyPI. In addition, you can then update your requirements.txt file to include your project package. This will ultimately prevent versioning issues, and ensure portability to other environments.
Automating Python packaging and workspace cleaning with Make commands
Automating Python packaging and workspace cleanup with Make commands brings tangible benefits to data scientists. By executing a single command, you can effortlessly generate a Python package using setup.py whilst removing the surplus files generated, leaving only the essential .whl file. This streamlined process ensures a clean and efficient packaging workflow. In the context of data science and Python projects, Makefiles become powerful tools, enabling automation of tasks such as cleaning up temporary files, running data preprocessing scripts, and maintaining organized, efficient workflows. In essence, Make is a build automation tool, and a Makefile is a set of rules defining what commands to run, offering data scientists a versatile means to speed up their development by automating simple CLI tasks.
To leverage Make commands on Windows, consider installing the Windows Subsystem for Linux (WSL) and setting up Ubuntu. Once this is setup, install Make in your Ubuntu environment. This will enable you to run Make commands directly from the Ubuntu Linux terminal within your Windows environment.
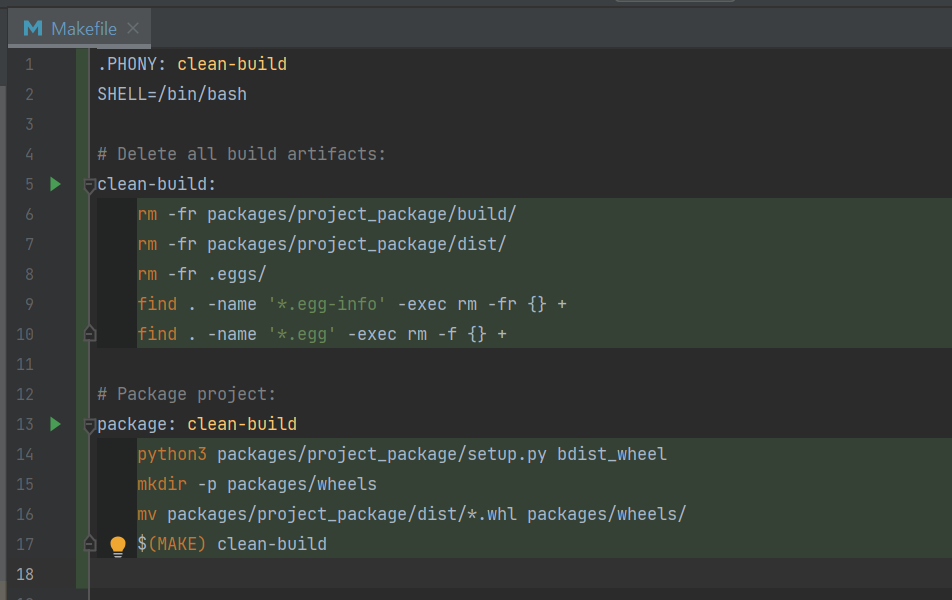
In our case, we have created a new file 'Makefile' in the root of our project directory (note that a Makefile has no file extension). We have then added Make commands to automate the process of creating our Python wheel, moving it into a folder named 'wheels', and deleting all other files that are generated by setup.py, see screenshot below.
We can now simply run our Make command 'package' using the following command executed in our Ubuntu terminal, note we execute the command from the root of the project directory (where the Makefile is saved):
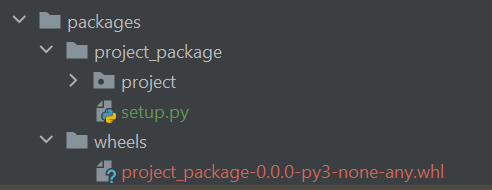
make packageOnce the command has finished executing, we can navigate back to our project, and find that a new folder has been created called 'wheels' which contains our new Python wheel file, whilst all other files generated by setup.py have been deleted, leaving us with a clean organised workspace.
In a real world project, we can then additionally extend our Make command to login to a private PyPI server and upload our Python wheel, from there we could add commands to pip install the PyPI hosted package in our environment, resulting in a full end-to-end workflow, orchestrated through a single Make command.
Final Words
Packaging up code into Python wheels can be an awkward process for a new data scientist, but through the use of Make commands, this process can be automated to a single command. Familiarizing yourself with Make can be very beneficial, as it will allow you to begin to automate many simple routine tasks, ultimately making you more productive.
Please find the tutorial repo here: https://github.com/jacobdylanjd/PyMessyToMasterpiece/tree/main
Comments